!pip install -Uqq accelerate
!pip install -Uqq transformersWhy and How to Fine-tune CLIP for remote sensing images

Traditional Image Classification models sometimes struggle with generalization in real-life situations. Moreover, labeling is a significant challenge when training these models, making it difficult for them to generalize across all cases. Enter CLIP (Text-Image pairing model), which benefits from recent developments in NLP (using Transformers) and the billions of image captions available on the Internet.
CLIP demonstrates less accuracy degradation in real-world scenarios compared to previous methods and introduces various exciting applications, such as searching for images using text, zero-shot learning classification, and more.
However, like many preceding deep learning models, even when CLIP is trained on an enormous dataset, it can encounter difficulties if there’s a mismatch between the domain of the inference data and the training data.
In this blog post, you’ll discover that CLIP, by default, doesn’t perform very well on remote-sensing datasets (images captured by satellites) and how we fine-tune the CLIP model using this new dataset.
Note
This blog-post inspired a lot from the example of contrastive-image-text from HuggingFace and this blog-post finetuning with Remote Sensing Images
Dataset used: rsicd
import transformerstransformers.__version__'4.33.2'How CLIP works
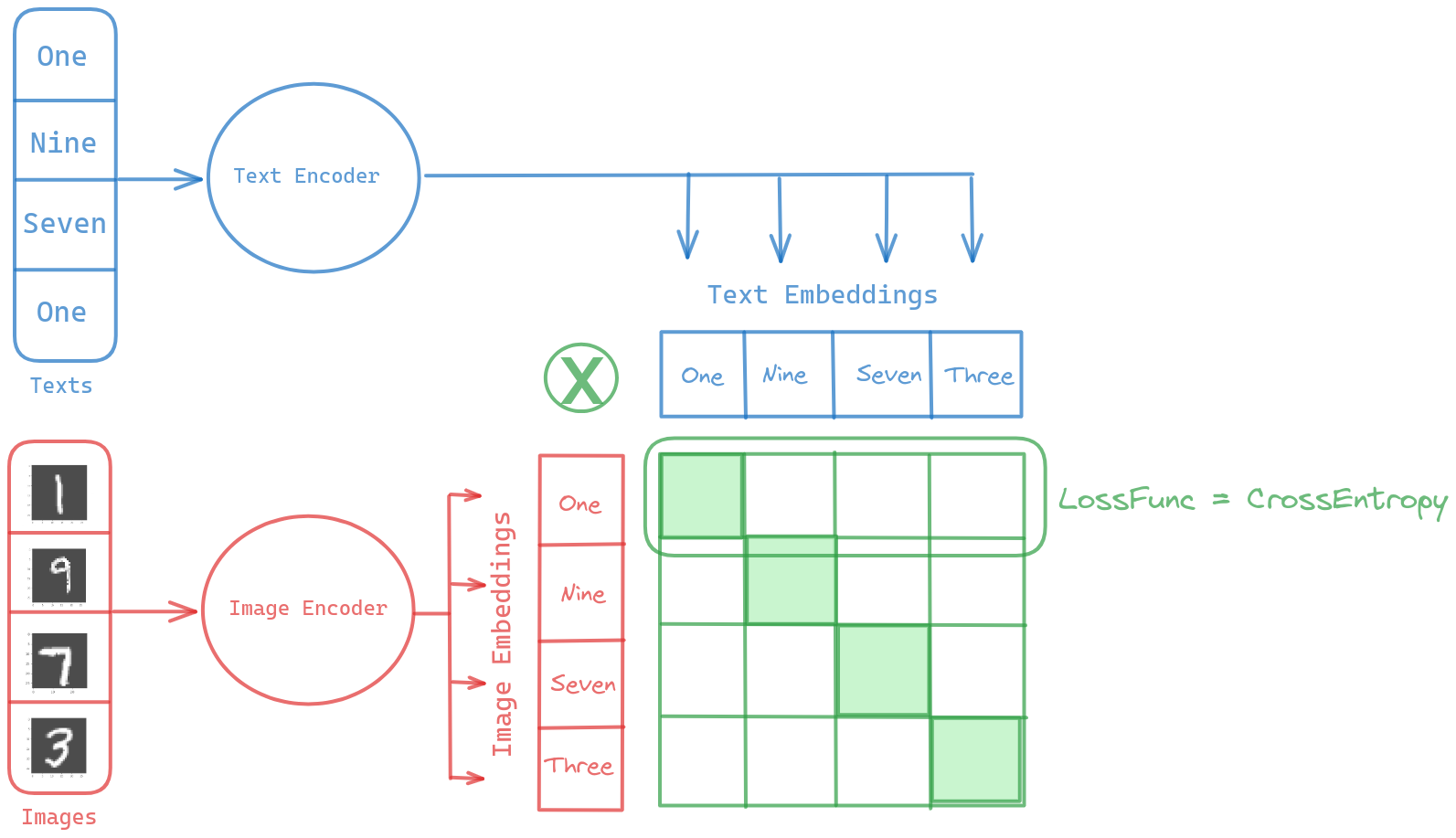
In a nutshell, the CLIP model leverages two pretrained models for text and image. It fine-tunes them in such a way that their embedding outputs for similar concepts become as close as possible
Imports
import os
import datasets
from dataclasses import dataclass, field
from typing import Optional
import matplotlib.pyplot as plt
import requests
import random
import numpy as np
import torch
from datasets import load_dataset
from PIL import Image
from torchvision.io import ImageReadMode, read_image
from torchvision.transforms import CenterCrop, ConvertImageDtype, Normalize, Resize
from torchvision.transforms.functional import InterpolationMode
from pdb import set_trace
import transformers
from transformers import (
VisionTextDualEncoderProcessor,
VisionTextDualEncoderModel,
AutoImageProcessor,
AutoModel,
AutoTokenizer,
HfArgumentParser,
Trainer,
TrainingArguments,
set_seed,
)
from transformers.trainer_utils import get_last_checkpoint
from transformers.utils import check_min_version, send_example_telemetry
from transformers.utils.versions import require_version
import warnings
warnings.filterwarnings('ignore', category=UserWarning, module='torchvision')
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.31.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/contrastive-image-text/requirements.txt")Base Model
As mentioned above, the Image Encoder for our CLIP is clip-vit-base-patch32 and Text Encoder is roberta-base
model = VisionTextDualEncoderModel.from_vision_text_pretrained(
"openai/clip-vit-base-patch32", "roberta-base"
)
tokenizer = AutoTokenizer.from_pretrained("roberta-base")
image_processor = AutoImageProcessor.from_pretrained("openai/clip-vit-base-patch32")
processor = VisionTextDualEncoderProcessor(image_processor, tokenizer)
model.save_pretrained("clip-roberta")
processor.save_pretrained("clip-roberta")Some weights of RobertaModel were not initialized from the model checkpoint at roberta-base and are newly initialized: ['roberta.pooler.dense.weight', 'roberta.pooler.dense.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
The projection layer and logit scale weights `['visual_projection.weight', 'text_projection.weight', 'logit_scale']` are newly initialized. You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Could not find image processor class in the image processor config or the model config. Loading based on pattern matching with the model's feature extractor configuration.Arguments
We define two argument classes: ModelArguments and HfArgumentParser. This allows us to utilize Hugging Face’s HfArgumentParser in conjunction with the default TrainingArguments from Hugging Face.
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"},
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
image_processor_name: str = field(default=None, metadata={"help": "Name or path of preprocessor config."})
cache_dir: Optional[str] = field(
default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
)
model_revision: str = field(
default="main",
metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
)
use_fast_tokenizer: bool = field(
default=True,
metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
)
use_auth_token: bool = field(
default=False,
metadata={
"help": (
"Will use the token generated when running `huggingface-cli login` (necessary to use this script "
"with private models)."
)
},
)@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
dataset_name: Optional[str] = field(
default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
)
data_dir: Optional[str] = field(default=None, metadata={"help": "The data directory containing input files."})
image_column: Optional[str] = field(
default="image_path",
metadata={"help": "The name of the column in the datasets containing the full image file paths."},
)
caption_column: Optional[str] = field(
default="caption",
metadata={"help": "The name of the column in the datasets containing the image captions."},
)
max_seq_length: Optional[int] = field(
default=128,
metadata={
"help": (
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
)
},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)args_dict = {'output_dir': './clip-roberta-finetuned',
'model_name_or_path': './clip-roberta',
'data_dir': './data',
'dataset_name': 'arampacha/rsicd',
'image_column': 'image',
'caption_column': 'captions',
'remove_unused_columns': False,
'per_device_train_batch_size': 64,
'per_device_eval_batch_size': 64,
'learning_rate': 5e-05,
'warmup_steps': 0,
'weight_decay': 0.1,
'overwrite_output_dir': True,
'push_to_hub': False}
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
model_args, data_args, training_args = parser.parse_dict(args_dict)model_args, data_args(ModelArguments(model_name_or_path='./clip-roberta', config_name=None, tokenizer_name=None, image_processor_name=None, cache_dir=None, model_revision='main', use_fast_tokenizer=True, use_auth_token=False),
DataTrainingArguments(dataset_name='arampacha/rsicd', data_dir='./data', image_column='image', caption_column='captions', max_seq_length=128, overwrite_cache=False, preprocessing_num_workers=None))Dataset Preparation
class Transform(torch.nn.Module):
def __init__(self, image_size, mean, std):
super().__init__()
self.transforms = torch.nn.Sequential(
Resize([image_size], interpolation=InterpolationMode.BICUBIC, antialias=True),
CenterCrop(image_size),
ConvertImageDtype(torch.float),
Normalize(mean, std),
)
def forward(self, x) -> torch.Tensor:
"""`x` should be an instance of `PIL.Image.Image`"""
with torch.no_grad():
x = self.transforms(x)
return xdef collate_fn(examples):
pixel_values = torch.stack([example["pixel_values"] for example in examples])
input_ids = torch.tensor([example["input_ids"] for example in examples], dtype=torch.long)
attention_mask = torch.tensor([example["attention_mask"] for example in examples], dtype=torch.long)
return {
"pixel_values": pixel_values,
"input_ids": input_ids,
"attention_mask": attention_mask,
"return_loss": True,
}Below is the remote sensing dataset that we use in this blog post
dataset = datasets.load_dataset("arampacha/rsicd")Found cached dataset parquet (/home/.cache/huggingface/datasets/arampacha___parquet/arampacha--rsicd-56e24d6cc63cb9d9/0.0.0/2a3b91fbd88a2c90d1dbbb32b460cf621d31bd5b05b934492fdef7d8d6f236ec)datasetDatasetDict({
train: Dataset({
features: ['filename', 'captions', 'image'],
num_rows: 8734
})
test: Dataset({
features: ['filename', 'captions', 'image'],
num_rows: 1093
})
valid: Dataset({
features: ['filename', 'captions', 'image'],
num_rows: 1094
})
})Let’s see examples of this dataset
def show_images(dset, num_images=8, without_caption=True,num_columns=2,img_size=(4, 4)):
num_rows = -(-num_images // num_columns) # Ceiling division
fig = plt.figure(figsize=(img_size[0] * num_columns, img_size[1] * num_rows))
_list = list(range(len(dset)))
for i in range(num_images):
index = _list[i]
ax = fig.add_subplot(num_rows, num_columns, i+1)
image = dset[index]['image']
plt.imshow(image)
# Set title as the first caption
if without_caption:
caption = dset[index]['captions'][0]
ax.set_title(caption, fontsize=10)
# Remove axis
plt.axis('off')
plt.tight_layout()
plt.subplots_adjust(wspace=0.5, hspace=0.01) # Adjust these values as needed
plt.show()show_images(dataset['train'], num_images=8, without_caption=True)
Model Preparation
tokenizer = AutoTokenizer.from_pretrained(
model_args.model_name_or_path, cache_dir=model_args.cache_dir, use_fast=model_args.use_fast_tokenizer
)image_processor = AutoImageProcessor.from_pretrained(
model_args.image_processor_name or model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
use_auth_token=True if model_args.use_auth_token else None,
)
model = AutoModel.from_pretrained(
model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
use_auth_token=True if model_args.use_auth_token else None,
)
config = model.configTo ensure reproducible output, we should set the seed.
set_seed(training_args.seed)image_transformations = Transform(
config.vision_config.image_size, image_processor.image_mean, image_processor.image_std
)
image_transformations = torch.jit.script(image_transformations)def tokenize_captions(examples):
captions = [example[0] for example in examples[data_args.caption_column]]
text_inputs = tokenizer(captions, max_length=data_args.max_seq_length, padding="max_length", truncation=True)
examples["input_ids"] = text_inputs.input_ids
examples["attention_mask"] = text_inputs.attention_mask
return examples
def transform_images(examples):
images = [torch.tensor(np.array(image)).permute(2, 0, 1) for image in examples[data_args.image_column]]
examples["pixel_values"] = [image_transformations(image) for image in images]
return examples
def filter_corrupt_images(examples):
"""remove problematic images"""
valid_images = []
for image_file in examples[data_args.image_column]:
try:
Image.open(image_file)
valid_images.append(True)
except Exception:
valid_images.append(False)
return valid_imagestrain_dataset = dataset["train"]
train_dataset = train_dataset.map(
function=tokenize_captions,
batched=True,
num_proc=data_args.preprocessing_num_workers,
load_from_cache_file=not data_args.overwrite_cache,
desc="Running tokenizer on train dataset",
)
train_dataset.set_transform(transform_images)Loading cached processed dataset at /home/.cache/huggingface/datasets/arampacha___parquet/arampacha--rsicd-56e24d6cc63cb9d9/0.0.0/2a3b91fbd88a2c90d1dbbb32b460cf621d31bd5b05b934492fdef7d8d6f236ec/cache-01af25c2d3c15faa.arrow
Parameter 'transform'=<function transform_images> of the transform datasets.arrow_dataset.Dataset.set_format couldn't be hashed properly, a random hash was used instead. Make sure your transforms and parameters are serializable with pickle or dill for the dataset fingerprinting and caching to work. If you reuse this transform, the caching mechanism will consider it to be different from the previous calls and recompute everything. This warning is only showed once. Subsequent hashing failures won't be showed.train_datasetDataset({
features: ['filename', 'captions', 'image', 'input_ids', 'attention_mask'],
num_rows: 8734
})eval_dataset = dataset["valid"]
eval_dataset = eval_dataset.map(
function=tokenize_captions,
batched=True,
num_proc=data_args.preprocessing_num_workers,
load_from_cache_file=not data_args.overwrite_cache,
desc="Running tokenizer on validation dataset",
)
eval_dataset.set_transform(transform_images)train_dataset, eval_dataset(Dataset({
features: ['filename', 'captions', 'image', 'input_ids', 'attention_mask'],
num_rows: 8734
}),
Dataset({
features: ['filename', 'captions', 'image', 'input_ids', 'attention_mask'],
num_rows: 1094
}))processor = VisionTextDualEncoderProcessor(image_processor, tokenizer)We have a straightforward example below (sourced from Hugging Face) to quickly demonstrate how the CLIP model works by default. There are two images: the first one is of a cat and the second is of a dog. We will use the text “a photo of a cat” and determine which picture has the highest probability.
urls = [
"http://images.cocodataset.org/val2017/000000039769.jpg",
"https://farm3.staticflickr.com/2674/5850229113_4fe05d5265_z.jpg",
]
images = [Image.open(requests.get(url, stream=True).raw) for url in urls]
inputs = processor(
text=["a photo of a cat"], images=images, return_tensors="pt", padding=True
)
inputs['input_ids'] = inputs['input_ids'].cuda()
inputs['attention_mask'] = inputs['attention_mask'].cuda()
inputs['pixel_values'] = inputs['pixel_values'].cuda()
model = model.cuda()
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image logits_per_imagetensor([[-0.9982],
[-0.5772]], device='cuda:0', grad_fn=<PermuteBackward0>)As you can see, the first picture is more likely to be of a cat (and that’s correct).
images[0]
images[1]
Finetuning CLIP
Take a look at how the default model performs with these remote-sensing images, which aren’t predominant in the training set. From a randomly selected set of 8 images, identify the first 3 images that correspond to the prompt “green trees.”
np.random.seed(0)
indices = np.random.choice(len(dataset['valid']), 8, replace=False)
patches = dataset['valid'].select(indices.tolist())show_images(patches, 8, without_caption=False, num_columns=4,img_size=(3, 3))
def show_result(model, patches, text, top_n = 3):
images = [patch['image'] for patch in patches]
inputs = processor(text=[text], images=images, return_tensors="pt", padding=True)
inputs['input_ids'] = inputs['input_ids'].cuda()
inputs['attention_mask'] = inputs['attention_mask'].cuda()
inputs['pixel_values'] = inputs['pixel_values'].cuda()
model = model.cuda()
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image
sorted_idx = (torch.sort(logits_per_image, dim=0, descending=True)[1][:,0]).tolist()
sorted_idx = sorted_idx[:top_n]
patches_sorted = patches.select(sorted_idx)
show_images(patches_sorted, num_images=len(patches_sorted), without_caption=False, num_columns=1, img_size=(3,3))show_result(model, patches, 'green trees')
Without fine-tuning, the performance isn’t optimal. As you can see, the first 3 images don’t showcase many trees.
# 8. Initalize our trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
data_collator=collate_fn,
)
# 9. Training
train_result = trainer.train()
trainer.log_metrics("train", train_result.metrics)
metrics = trainer.evaluate()
trainer.log_metrics("eval", metrics)/opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py:1501: UserWarning: operator() profile_node %380 : int = prim::profile_ivalue(%out_dtype.1)
does not have profile information (Triggered internally at /opt/conda/conda-bld/pytorch_1678411187366/work/third_party/nvfuser/csrc/graph_fuser.cpp:104.)
return forward_call(*args, **kwargs)
[411/411 06:42, Epoch 3/3]
| Step | Training Loss |
|---|
***** train metrics *****
epoch = 3.0
total_flos = 3258157GF
train_loss = 1.7008
train_runtime = 0:06:44.15
train_samples_per_second = 64.832
train_steps_per_second = 1.017
[18/18 00:06]
***** eval metrics *****
epoch = 3.0
eval_loss = 3.8048
eval_runtime = 0:00:07.26
eval_samples_per_second = 150.574
eval_steps_per_second = 2.477show_result(model, patches, 'green trees')
After finetuning the result is much better!! There are trees in all 3 images