!pip install -qq speechbrain
!pip install -qq seaborn
!pip install -Uqq huggingface_hub
!pip install -Uqq fastai
!pip install -Uqq wandbMy Experiments to winning the CryCeleb Competition (Audio Verification)
![]()
This blog post is to document my journey to winning the CryCeleb competition hosted by HuggingFace and Ubenwa, which focuses on verifying babies using their cry sound. However, I must admit that:
- I don’t track all of my experiments and don’t really remember which approach give me this position
Why?
Initially, my plan was to document all my experiments once I had established a reliable baseline. Unfortunately, this never happened. None of the strategies I used provided me with any significant indication that they were drastically more effective than merely augmenting the host’s baseline model with Test Time Augmentation (TTA) (given that the dev set and the public set is quite small)
Not developing a library in maintaining an organized record of my experiments. As the codebase for my experiments expanded, it became increasingly difficult to manage and track everything.
Advice for future competitions:
- Begin by building a library with nbdev. This will naturally facilitate easier tracking of experiments.
What I have tried
- Implementing a Siamese Network with Spectrogram Image
- Employing a Siamese Network with an ECAPA model - Contrastive Loss MSE/MAE
- Utilizing a Siamese Network with an ECAPA model - Contrastive Loss for Cosine Similarity
- Applying an ECAPA Network with various hyperparameters and Label Smoothing for the loss function (Final Submission)
During test inference, I employed Test Time Augmentation, randomly pairing 7x7 slices of sound duration ranging from 3s to 15s.
All my experiments, with the exception of the last one, are unsuccessful, as none of them delivered robust metrics on the dev set.
Siamese Network with Spectrogram Image
Having previously succeeded in an Audio Classification competition, I initiated this challenge using a Siamese Network for an Image Classification approach. This involved converting the audio into a spectrogram image and using a ResNet model as the backbone. However, the results were disappointing.
Siamese Network with an ECAPA model - Contrastive Loss MSE/MAE
Unable to initially surpass the baseline model, I began experimenting with a Siamese Network in conjunction with the baseline. However, due to a lack of understanding of the inner workings of the ECAPA model, I naively used MAE/MSE as the loss function. Unsurprisingly, the results were quite unsatisfactory.
Siamese Network with an ECAPA model - Contrastive Loss for Cosine Similarity
After realizing that the ECAPA model was designed to maximize the angle between different classes, I attempted to modify the Contrastive Loss function. Instead of using the MAE/MSE Loss, I employed Cosine Similarity. I had high hopes for this method, but unfortunately, it didn’t work. After a few epochs, the loss pushed towards the extreme values of -1 and 1, a phenomenon I still can’t explain.
ECAPA Network with various hyperparameters and Label Smoothing for the loss function
In response to these setbacks, I returned to the baseline model, making some adjustments to the hyperparameters to create a larger model than the baseline, and added label smoothing.
Final Experiment
import speechbrain as sb
from speechbrain.pretrained import SpeakerRecognition, EncoderClassifier
from speechbrain.dataio.dataio import read_audio
from speechbrain.utils.metric_stats import EER
import pandas as pd
import numpy as np
import torch
import seaborn as sns
import matplotlib.pyplot as plt
from huggingface_hub import hf_hub_download
from tqdm.notebook import tqdm
import random
from speechbrain.processing.features import InputNormalization
from speechbrain.lobes.features import Fbank
import seaborn as sns
from itertools import combinations, productfrom fastai.vision.all import *
from torch.utils.data import Dataset, DataLoaderimport wandb
from fastai.callback.wandb import *
wandb.init("cryceleb")wandb: Currently logged in as: dhoa. Use `wandb login --relogin` to force relogin
Tracking run with wandb version 0.15.5
Run data is saved locally in
/home/wandb/run-20230710_211533-s4lz49ck
View project at https://wandb.ai/dhoa/uncategorized
# read metadata
metadata = pd.read_csv(f'metadata.csv', dtype={'baby_id':str, 'chronological_index':str})
dev_metadata = metadata.loc[metadata['split']=='dev'].copy()
# read sample submission
sample_submission = pd.read_csv(f"sample_submission.csv") # scores are unfiorm random
# read verification pairs
dev_pairs = pd.read_csv(f"dev_pairs.csv", dtype={'baby_id_B':str, 'baby_id_D':str})
test_pairs = pd.read_csv(f"test_pairs.csv")
display(metadata.head().style.set_caption(f"metadata").set_table_styles([{'selector': 'caption','props': [('font-size', '20px')]}]))
display(dev_pairs.head().style.set_caption(f"dev_pairs").set_table_styles([{'selector': 'caption','props': [('font-size', '20px')]}]))
display(test_pairs.head().style.set_caption(f"test_pairs").set_table_styles([{'selector': 'caption','props': [('font-size', '20px')]}]))
display(sample_submission.head().style.set_caption(f"sample_submission").set_table_styles([{'selector': 'caption','props': [('font-size', '20px')]}]))| baby_id | period | duration | split | chronological_index | file_name | file_id | |
|---|---|---|---|---|---|---|---|
| 0 | 0694 | B | 1.320000 | dev | 000 | audio/dev/0694/B/0694_B_000.wav | 0694_B_000 |
| 1 | 0694 | B | 0.940000 | dev | 001 | audio/dev/0694/B/0694_B_001.wav | 0694_B_001 |
| 2 | 0694 | B | 0.880000 | dev | 002 | audio/dev/0694/B/0694_B_002.wav | 0694_B_002 |
| 3 | 0694 | B | 1.130000 | dev | 003 | audio/dev/0694/B/0694_B_003.wav | 0694_B_003 |
| 4 | 0694 | B | 1.180000 | dev | 004 | audio/dev/0694/B/0694_B_004.wav | 0694_B_004 |
| baby_id_B | baby_id_D | id | label | |
|---|---|---|---|---|
| 0 | 0133 | 0611 | 0133B_0611D | 0 |
| 1 | 0593 | 0584 | 0593B_0584D | 0 |
| 2 | 0094 | 0292 | 0094B_0292D | 0 |
| 3 | 0563 | 0094 | 0563B_0094D | 0 |
| 4 | 0122 | 0694 | 0122B_0694D | 0 |
| baby_id_B | baby_id_D | id | |
|---|---|---|---|
| 0 | anonymous027 | anonymous212 | anonymous027B_anonymous212D |
| 1 | anonymous035 | anonymous225 | anonymous035B_anonymous225D |
| 2 | anonymous029 | anonymous288 | anonymous029B_anonymous288D |
| 3 | anonymous001 | anonymous204 | anonymous001B_anonymous204D |
| 4 | anonymous075 | anonymous244 | anonymous075B_anonymous244D |
| id | score | |
|---|---|---|
| 0 | anonymous027B_anonymous212D | 0.548814 |
| 1 | anonymous035B_anonymous225D | 0.715189 |
| 2 | anonymous029B_anonymous288D | 0.602763 |
| 3 | anonymous001B_anonymous204D | 0.544883 |
| 4 | anonymous075B_anonymous244D | 0.423655 |
Ubenwa Baseline
I reproduced the baseline from code, excluding the config file. This facilitated easier customization of the code according to my needs, and allowed for the use of a more high level framework like fastai. The following are some code snippets from speechbrain for the ecapa model.
class InputNormalizationFixedSize(InputNormalization):
def forward(self, x):
N_batches = x.shape[0]
current_means = []
current_stds = []
for snt_id in range(N_batches):
# Avoiding padded time steps
actual_size = torch.round(torch.tensor(1) * x.shape[1]).int()
# computing statistics
current_mean, current_std = self._compute_current_stats(
x[snt_id, 0:actual_size, ...]
)
current_means.append(current_mean)
current_stds.append(current_std)
if self.norm_type == "sentence":
x[snt_id] = (x[snt_id] - current_mean.data) / current_std.data
return xnormalizer = InputNormalizationFixedSize(norm_type='sentence', std_norm=False)feature_maker = Fbank(deltas=False,
n_mels=80,
left_frames=0,
right_frames=0,
)dataset_path = './'
metadata = pd.read_csv(
f"{dataset_path}/metadata.csv", dtype={"baby_id": str, "chronological_index": str}
)
dev_metadata = metadata.loc[metadata["split"] == "dev"].copy()
sample_submission = pd.read_csv(
f"{dataset_path}/sample_submission.csv"
)
dev_pairs = pd.read_csv(
f"{dataset_path}/dev_pairs.csv", dtype={"baby_id_B": str, "baby_id_D": str}
)
test_pairs = pd.read_csv(f"{dataset_path}/test_pairs.csv")encoder = SpeakerRecognition.from_hparams(
source="Ubenwa/ecapa-voxceleb-ft-cryceleb",
savedir=f"ecapa-voxceleb-ft-cryceleb",
run_opts={"device":"cuda"} #comment out if no GPU available
)embedding_model = encoder.mods.embedding_modeldef shuffle_group_and_concat(x, n=8):
""" Shuffle sound data per row and concat """
concatenated_results = []
for _ in range(n):
shuffled_values = x.values.copy()
random.shuffle(shuffled_values)
concatenated = np.concatenate(shuffled_values)
tensor_length = concatenated.shape[0]
if tensor_length < 16000*3:
raw_audio = np.tile(concatenated, math.ceil(16000*7 / tensor_length))
concatenated = concatenated[:random.randint(16000*3, 16000*15)]
concatenated_results.append(concatenated)
return concatenated_resultsdef compute_cosine_similarity_score(row, cry_dict):
""" Average scores for all possible pairs """
cos = torch.nn.CosineSimilarity(dim=-1)
encoded_cry_B = cry_dict[(row['baby_id_B'], 'B')]['cry_encoded']
encoded_cry_D = cry_dict[(row['baby_id_D'], 'D')]['cry_encoded']
similarity_scores = []
for tensor_B in encoded_cry_B:
for tensor_D in encoded_cry_D:
similarity_score = cos(tensor_B, tensor_D)
similarity_scores.append(similarity_score.item())
return sum(similarity_scores) / len(similarity_scores)dev_metadata = metadata.loc[metadata['split']=='dev'].copy()
dev_metadata['cry'] = dev_metadata.apply(lambda row: read_audio(row['file_name']).numpy(), axis=1)
grouped_data = dev_metadata.groupby(['baby_id', 'period'])['cry']
cry_dict = {}
for key, group in grouped_data:
cry_dict[key] = {'cry': shuffle_group_and_concat(group, 7)}def encode(embedding_model, item):
""" Encoding audio for ECAPA model including: Feature_maker, Normalizer, Embedding Model """
is_training = embedding_model.training
if is_training: embedding_model.eval()
item = item.unsqueeze(0)
feats = feature_maker(item.cuda())
feats = normalizer(feats)
embeddings = embedding_model(feats)
if is_training: embedding_model.train()
return embeddingsdef compute_eer_and_plot_verification_scores(pairs_df, plot=True):
''' pairs_df must have 'score' and 'label' columns'''
positive_scores = pairs_df.loc[pairs_df['label']==1]['score'].values
negative_scores = pairs_df.loc[pairs_df['label']==0]['score'].values
eer, threshold = EER(torch.tensor(positive_scores), torch.tensor(negative_scores))
if plot:
ax = sns.histplot(pairs_df, x='score', hue='label', stat='percent', common_norm=False)
ax.set_title(f'EER={round(eer, 4)} - Thresh={round(threshold, 4)}')
plt.axvline(x=[threshold], color='red', ls='--');
print(eer)
return eer, thresholddef get_eer(embedding_model, cry_dict, df, tta_nb = 8, plot=True, ):
embedding_model.eval()
for key, group in grouped_data:
cry_dict[key] = {'cry': shuffle_group_and_concat(group, tta_nb)}
with torch.no_grad():
embedding_model = embedding_model
if plot:
loop = tqdm(cry_dict.items())
else:
loop = cry_dict.items()
for (baby_id, period), d in loop:
cry_array = d['cry']
cry_encoded_list = []
for row in cry_array:
encoded_row = encode(embedding_model.cuda(), torch.tensor(row).cuda())
encoded_row = encoded_row.cpu()
cry_encoded_list.append(encoded_row)
d['cry_encoded'] = cry_encoded_list
df['score'] = dev_pairs.apply(lambda row: compute_cosine_similarity_score(row=row, cry_dict=cry_dict), axis=1)
eer, threshold = compute_eer_and_plot_verification_scores(pairs_df=df, plot=plot)
embedding_model.train()
return eer, thresholdget_eer(embedding_model, cry_dict, dev_pairs)/opt/conda/lib/python3.10/site-packages/torch/functional.py:641: UserWarning: stft with return_complex=False is deprecated. In a future pytorch release, stft will return complex tensors for all inputs, and return_complex=False will raise an error.
Note: you can still call torch.view_as_real on the complex output to recover the old return format. (Triggered internally at /opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/SpectralOps.cpp:862.)
return _VF.stft(input, n_fft, hop_length, win_length, window, # type: ignore[attr-defined]0.22499999403953552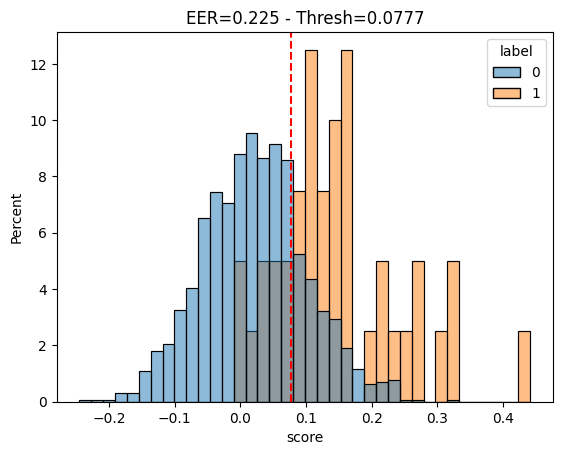
Dataset
def get_pair_item(item):
if item.name == 'B':
pair_name = 'D'
else:
pair_name = 'B'
return item.parent / pair_namefiles = metadata['file_name'].values
folders = [Path(file).parent for file in files]
folders = list(set(folders))len(folders)1334def read_audio_from_list(paths):
raw_audios_aug = []
random.shuffle(paths)
raw_audio = torch.concat([read_audio(str(filename)) for filename in paths])
tensor_length = raw_audio.shape[0]
if tensor_length < 16000*3:
raw_audio = raw_audio.repeat(math.ceil(16000*5 / tensor_length))
return raw_audiotrain_folders = [folder for folder in folders if folder.parent.parent.name in ['train']]
dev_folders = [folder for folder in folders if folder.parent.parent.name in ['dev']]
full_folders = train_folders + dev_folders
pair_folders = [folder for folder in train_folders if get_pair_item(folder).exists()]len(full_folders) ,len(train_folders), len(dev_folders), len(pair_folders)(1014, 934, 80, 696)### get both id from train and dev
baby_ids = metadata[(metadata['split'] == 'train')]['baby_id'].unique()
baby_ids = np.sort(baby_ids)
n_classes = len(baby_ids)
print(n_classes)586id2idx = {baby_id: index for index, baby_id in enumerate(baby_ids)}files = metadata['file_name'].values
folders = [Path(file).parent for file in files]
folders = list(set(folders))full_folders = [folder for folder in folders if folder.parent.parent.name in ['train', 'dev']]
train_folders_pairs = [folder for folder in train_folders if get_pair_item(folder).exists()]
baby_ids_pairs = list(set([folder.parent.name for folder in train_folders_pairs]))
valid_folders = [Path('audio/train')/_id/ random.choice(['B','D']) for _id in baby_ids_pairs ]
train_folders = [folder for folder in train_folders if folder not in valid_folders]len(full_folders) ,len(train_folders), len(dev_folders), len(pair_folders)(1014, 586, 80, 696)train_meta = metadata[metadata['split'] == 'train']
dev_meta = metadata[metadata['split'] == 'dev']
test_meta = metadata[metadata['split'] == 'test']# train_folders_not_pairs = [folder for folder in train_folders if not get_pair_item(folder).exists()]def read_audio_from_folder(folder, shuffle = True):
if shuffle == True:
files = [str(filename) for filename in folder.ls().shuffle() if filename.suffix == '.wav']
else:
files = [str(filename) for filename in folder.ls() if filename.suffix == '.wav']
raw_audio = torch.concat([read_audio(str(filename)) for filename in files])
tensor_length = raw_audio.shape[0]
if tensor_length < 16000*3:
raw_audio = raw_audio.repeat(math.ceil(16000*6 / tensor_length))
return raw_audiodef get_label(folder):
return id2idx[folder.parent.name]class CryCelebDset(Dataset):
def __init__(self,
items):
super(CryCelebDset, self).__init__()
self.items = items
def __len__(self):
return len(self.items)
def __getitem__(self, i):
item = self.items[i]
audio = read_audio_from_folder(item)
label = get_label(item)
return audio, torch.Tensor([label]).long()def collate_fn(batch):
audios, labels = zip(*batch)
target_lenth = min(audio.shape[0] for audio in audios)
target_lenth = target_lenth if target_lenth < 16000*3 else min(target_lenth, random.randint(16000*3, 16000*8))
audios = [audio[:target_lenth] for audio in audios]
return torch.stack(audios), torch.stack(labels)# train_dset = CryCelebDset(train_folders)
train_dset = CryCelebDset(train_folders)
valid_dset = CryCelebDset(train_folders[:2]) # Validation is no use here, it is just a hack to make fastai worklen(train_dset), len(valid_dset)(586, 2)train_loader = DataLoader(train_dset, batch_size=16, shuffle=True, collate_fn=collate_fn)
valid_loader = DataLoader(valid_dset, batch_size=32, shuffle=False, collate_fn=collate_fn)dls = DataLoaders(train_loader, valid_loader)Model
The model here shares the same architecture as the ECAPA model, but there are some differences in the hyperparameters, such as n_mels = 150, lin_neurons = 250. My intention was to experiment with a larger version of the default ECAPA model.
There is a minor modification in the loss function: I added label_smoothing with a value of 0.05.
import torch.nn.functional as F
from torch import nn
class Classifier(nn.Module):
def __init__(
self,
input_size,
device="cpu",
lin_neurons=192,
out_neurons=1211,
dropout_rate=0.5, # add a dropout_rate parameter
):
super().__init__()
self.linear = nn.Linear(input_size, lin_neurons)
self.dropout = nn.Dropout(dropout_rate)
# Final Layer
self.weight = nn.Parameter(
torch.FloatTensor(out_neurons, lin_neurons).to(device)
)
nn.init.xavier_uniform_(self.weight)
def forward(self, x):
x = self.linear(x)
x = self.dropout(x)
# Need to be normalized
x = F.linear(F.normalize(x.squeeze(1)), F.normalize(self.weight))
return x.unsqueeze(1)def is_model_frozen(model):
return all(not param.requires_grad for param in model.parameters())
def unfreeze_model(model):
for param in model.parameters():
param.requires_grad = True
unfreeze_model(embedding_model)
print(is_model_frozen(embedding_model)) Falsen_mels = 150
lin_neurons = 250
# n_mels = 80
# lin_neurons = 192
feature_maker = sb.lobes.features.Fbank(deltas=False,
n_mels=n_mels,
left_frames=0,
right_frames=0,
)
embedding_model = sb.lobes.models.ECAPA_TDNN.ECAPA_TDNN(input_size=n_mels,
channels=[1024, 1024, 1024, 1024, 3072],
kernel_sizes=[5, 3, 3, 3, 1],
dilations=[1, 2, 3, 4, 1],
groups=[1, 1, 1, 1, 1],
attention_channels=128,
lin_neurons=lin_neurons
)
classifier = sb.lobes.models.ECAPA_TDNN.Classifier(input_size=lin_neurons,
out_neurons=n_classes,
)
class Model(nn.Module):
def __init__(self, feature_maker, normalizer, embedding_model, classifier):
super(Model, self).__init__()
self.feature_maker = feature_maker
self.normalizer = normalizer
self.embedding_model = embedding_model
self.classifier = classifier
def forward(self, x):
feats = self.feature_maker(x)
feats = self.normalizer(feats)
embeddings = self.embedding_model(feats)
classifier_outputs = self.classifier(embeddings)
return classifier_outputs
model = Model(feature_maker = feature_maker,
normalizer=normalizer,
embedding_model=embedding_model,
classifier=classifier)class LogSoftmaxWrapperSmoothing(nn.Module):
def __init__(self, loss_fn, smoothing=0.05): # add a smoothing parameter
super(LogSoftmaxWrapperSmoothing, self).__init__()
self.loss_fn = loss_fn
self.criterion = torch.nn.KLDivLoss(reduction="sum")
self.smoothing = smoothing # store the smoothing value
def forward(self, outputs, targets, length=None):
outputs = outputs.squeeze(1)
targets = targets.squeeze(1)
targets = F.one_hot(targets.long(), outputs.shape[1]).float()
# Apply label smoothing
targets = (1 - self.smoothing) * targets + self.smoothing / outputs.shape[1]
try:
predictions = self.loss_fn(outputs, targets)
except TypeError:
predictions = self.loss_fn(outputs)
predictions = F.log_softmax(predictions, dim=1)
loss = self.criterion(predictions, targets) / targets.sum()
return loss
loss_base = sb.nnet.losses.AdditiveAngularMargin(margin=0.2, scale=30)
crit = LogSoftmaxWrapperSmoothing(loss_base)
def loss_fn(preds, targets):
return crit(preds, targets)def eer_metric(preds, targs):
# The eer metric here is not related to the validation set but the dev set
eer, threshold = get_eer(embedding_model, cry_dict, dev_pairs, plot=False)
return eerlearner = Learner(dls, model, loss_func=loss_fn, metrics=[eer_metric], cbs=WandbCallback())learner.lr_find()SuggestedLRs(valley=9.120108734350652e-05)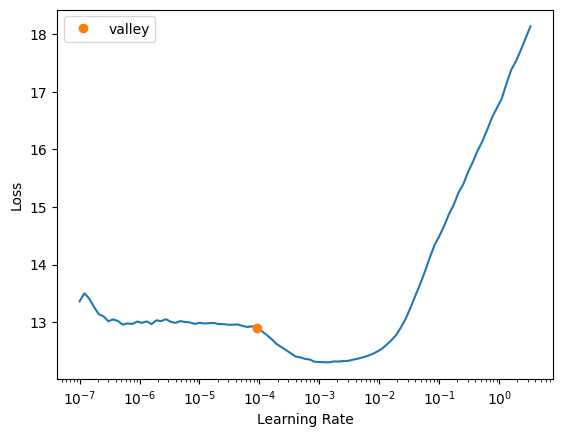
learner.fit_one_cycle(150, 2e-4)Could not gather input dimensions
WandbCallback was not able to prepare a DataLoader for logging prediction samples -> 'DataLoader' object has no attribute 'new'| epoch | train_loss | valid_loss | eer_metric | time |
|---|---|---|---|---|
| 0 | 12.819111 | 9.852398 | 0.397115 | 00:21 |
| 1 | 11.732524 | 9.378596 | 0.369231 | 00:20 |
| 2 | 10.952858 | 6.739351 | 0.375000 | 00:19 |
| 3 | 10.304280 | 8.235709 | 0.350000 | 00:18 |
| 4 | 9.576555 | 6.657913 | 0.375000 | 00:18 |
| 5 | 8.874806 | 7.752380 | 0.350962 | 00:18 |
| 6 | 8.028608 | 4.957489 | 0.325000 | 00:17 |
| 7 | 7.302641 | 5.177752 | 0.301923 | 00:17 |
| 8 | 6.496997 | 4.656638 | 0.350000 | 00:17 |
| 9 | 5.806657 | 5.101495 | 0.325000 | 00:17 |
| 10 | 4.984231 | 2.045478 | 0.350000 | 00:18 |
| 11 | 4.510298 | 1.314584 | 0.327244 | 00:18 |
| 12 | 3.988340 | 0.315158 | 0.326603 | 00:17 |
| 13 | 3.477479 | 5.352105 | 0.325000 | 00:17 |
| 14 | 3.133040 | 0.237394 | 0.320833 | 00:17 |
| 15 | 2.831013 | 1.140466 | 0.350000 | 00:17 |
| 16 | 2.446104 | 0.798410 | 0.352244 | 00:18 |
| 17 | 2.167508 | 0.486705 | 0.325000 | 00:17 |
| 18 | 2.059879 | 1.214511 | 0.325000 | 00:17 |
| 19 | 1.854602 | 2.260158 | 0.350000 | 00:17 |
| 20 | 1.853107 | 0.357835 | 0.300000 | 00:17 |
| 21 | 1.740630 | 1.374100 | 0.325000 | 00:17 |
| 22 | 1.724865 | 0.170533 | 0.325000 | 00:18 |
| 23 | 1.595109 | 0.166785 | 0.297756 | 00:17 |
| 24 | 1.476745 | 0.489945 | 0.300000 | 00:17 |
| 25 | 1.364003 | 0.830093 | 0.347436 | 00:17 |
| 26 | 1.368073 | 0.172278 | 0.325000 | 00:17 |
| 27 | 1.400348 | 0.264813 | 0.350000 | 00:17 |
| 28 | 1.357518 | 0.213733 | 0.354487 | 00:17 |
| 29 | 1.350938 | 0.121906 | 0.306090 | 00:17 |
| 30 | 1.298094 | 0.797013 | 0.275000 | 00:17 |
| 31 | 1.163949 | 0.125197 | 0.325000 | 00:18 |
| 32 | 0.992551 | 0.494040 | 0.303846 | 00:18 |
| 33 | 0.929511 | 0.315667 | 0.350000 | 00:17 |
| 34 | 0.970226 | 0.303382 | 0.326603 | 00:17 |
| 35 | 1.001400 | 0.403191 | 0.325000 | 00:17 |
| 36 | 1.044940 | 0.573968 | 0.325000 | 00:17 |
| 37 | 0.906172 | 0.145333 | 0.300000 | 00:17 |
| 38 | 0.842299 | 0.281313 | 0.304167 | 00:17 |
| 39 | 0.871641 | 0.217045 | 0.350000 | 00:17 |
| 40 | 0.777124 | 0.131117 | 0.300000 | 00:17 |
| 41 | 0.705075 | 0.207996 | 0.276282 | 00:17 |
| 42 | 0.711332 | 0.606886 | 0.300000 | 00:17 |
| 43 | 0.756493 | 0.504772 | 0.325000 | 00:17 |
| 44 | 0.703369 | 0.255737 | 0.325000 | 00:18 |
| 45 | 0.670267 | 1.306089 | 0.276282 | 00:17 |
| 46 | 0.645874 | 0.156841 | 0.325000 | 00:17 |
| 47 | 0.648763 | 0.117524 | 0.325000 | 00:17 |
| 48 | 0.561911 | 0.229732 | 0.300000 | 00:17 |
| 49 | 0.529512 | 0.191458 | 0.295192 | 00:17 |
| 50 | 0.462782 | 0.167080 | 0.277244 | 00:18 |
| 51 | 0.496077 | 0.106041 | 0.275000 | 00:17 |
| 52 | 0.501537 | 0.292876 | 0.277244 | 00:17 |
| 53 | 0.470838 | 0.200016 | 0.306090 | 00:17 |
| 54 | 0.492161 | 0.140463 | 0.256090 | 00:17 |
| 55 | 0.490079 | 0.254963 | 0.256090 | 00:17 |
| 56 | 0.452705 | 0.186381 | 0.277885 | 00:17 |
| 57 | 0.422567 | 0.180647 | 0.274359 | 00:18 |
| 58 | 0.458263 | 0.916696 | 0.272756 | 00:17 |
| 59 | 0.445988 | 0.176482 | 0.250000 | 00:17 |
| 60 | 0.449376 | 0.134938 | 0.300000 | 00:17 |
| 61 | 0.398278 | 0.454310 | 0.274359 | 00:18 |
| 62 | 0.378900 | 0.136589 | 0.300000 | 00:18 |
| 63 | 0.397175 | 0.266560 | 0.346795 | 00:17 |
| 64 | 0.419594 | 0.166931 | 0.275000 | 00:17 |
| 65 | 0.408431 | 0.162984 | 0.322436 | 00:18 |
| 66 | 0.429785 | 0.227120 | 0.344872 | 00:17 |
| 67 | 0.380197 | 0.282507 | 0.325000 | 00:17 |
| 68 | 0.361336 | 0.403791 | 0.299359 | 00:18 |
| 69 | 0.348556 | 0.501471 | 0.277244 | 00:18 |
| 70 | 0.360931 | 0.358086 | 0.275000 | 00:17 |
| 71 | 0.336917 | 0.388072 | 0.350000 | 00:17 |
| 72 | 0.335198 | 0.326303 | 0.275000 | 00:18 |
| 73 | 0.318928 | 0.230708 | 0.350000 | 00:17 |
| 74 | 0.337089 | 0.224751 | 0.300000 | 00:17 |
| 75 | 0.347762 | 0.228684 | 0.295192 | 00:17 |
| 76 | 0.347869 | 0.283976 | 0.275000 | 00:17 |
| 77 | 0.328355 | 0.148460 | 0.300000 | 00:17 |
| 78 | 0.301195 | 0.314673 | 0.300000 | 00:18 |
| 79 | 0.309706 | 0.219821 | 0.330769 | 00:18 |
| 80 | 0.313028 | 0.351390 | 0.375000 | 00:17 |
| 81 | 0.311351 | 0.203537 | 0.374038 | 00:17 |
| 82 | 0.278428 | 0.227288 | 0.326603 | 00:17 |
| 83 | 0.300168 | 0.120307 | 0.300000 | 00:17 |
| 84 | 0.291518 | 0.273817 | 0.305128 | 00:18 |
| 85 | 0.286973 | 0.276371 | 0.324679 | 00:17 |
| 86 | 0.292313 | 0.201308 | 0.300000 | 00:18 |
| 87 | 0.286953 | 0.333281 | 0.279167 | 00:17 |
| 88 | 0.278925 | 0.292981 | 0.321154 | 00:17 |
| 89 | 0.254643 | 0.312703 | 0.254487 | 00:18 |
| 90 | 0.256090 | 0.102150 | 0.275000 | 00:17 |
| 91 | 0.256988 | 0.243337 | 0.250000 | 00:17 |
| 92 | 0.247612 | 1.446797 | 0.250000 | 00:18 |
| 93 | 0.240916 | 0.104841 | 0.300000 | 00:17 |
| 94 | 0.239867 | 0.203033 | 0.300000 | 00:18 |
| 95 | 0.250558 | 0.213792 | 0.300000 | 00:17 |
| 96 | 0.225012 | 0.146971 | 0.325000 | 00:18 |
| 97 | 0.250202 | 0.144672 | 0.322436 | 00:18 |
| 98 | 0.252809 | 0.223730 | 0.300000 | 00:18 |
| 99 | 0.247364 | 0.127707 | 0.303846 | 00:17 |
| 100 | 0.236257 | 0.200906 | 0.300000 | 00:17 |
| 101 | 0.215899 | 0.222088 | 0.275000 | 00:18 |
| 102 | 0.211499 | 0.264478 | 0.325000 | 00:17 |
| 103 | 0.220157 | 0.327042 | 0.278846 | 00:17 |
| 104 | 0.217344 | 0.180306 | 0.251282 | 00:17 |
| 105 | 0.211273 | 0.191087 | 0.325000 | 00:18 |
| 106 | 0.225987 | 0.226452 | 0.324679 | 00:18 |
| 107 | 0.234045 | 0.162532 | 0.300000 | 00:17 |
| 108 | 0.216443 | 0.187482 | 0.275000 | 00:18 |
| 109 | 0.211505 | 0.156684 | 0.276603 | 00:18 |
| 110 | 0.210457 | 0.178876 | 0.275000 | 00:17 |
| 111 | 0.203583 | 0.097995 | 0.280128 | 00:17 |
| 112 | 0.200213 | 0.150823 | 0.300000 | 00:18 |
| 113 | 0.205306 | 0.091030 | 0.275000 | 00:17 |
| 114 | 0.195609 | 0.419262 | 0.253205 | 00:17 |
| 115 | 0.184044 | 0.157910 | 0.269231 | 00:18 |
| 116 | 0.182212 | 0.235523 | 0.275000 | 00:18 |
| 117 | 0.177163 | 0.177653 | 0.275000 | 00:18 |
| 118 | 0.181401 | 0.236190 | 0.269551 | 00:17 |
| 119 | 0.175148 | 0.269990 | 0.269231 | 00:17 |
| 120 | 0.176068 | 0.224078 | 0.319872 | 00:18 |
| 121 | 0.185972 | 0.157348 | 0.275000 | 00:17 |
| 122 | 0.174520 | 0.167444 | 0.300000 | 00:18 |
| 123 | 0.177205 | 0.214876 | 0.300000 | 00:18 |
| 124 | 0.166557 | 0.090736 | 0.297756 | 00:18 |
| 125 | 0.167413 | 0.265629 | 0.325000 | 00:17 |
| 126 | 0.164617 | 0.261985 | 0.325000 | 00:18 |
| 127 | 0.167717 | 0.223148 | 0.256090 | 00:17 |
| 128 | 0.160176 | 0.159316 | 0.325000 | 00:17 |
| 129 | 0.155260 | 0.159374 | 0.300000 | 00:18 |
| 130 | 0.154295 | 0.176301 | 0.272115 | 00:17 |
| 131 | 0.149302 | 0.210373 | 0.275000 | 00:17 |
| 132 | 0.156900 | 0.168842 | 0.300000 | 00:17 |
| 133 | 0.150621 | 0.171651 | 0.274038 | 00:17 |
| 134 | 0.150258 | 0.184598 | 0.278526 | 00:18 |
| 135 | 0.152160 | 0.148298 | 0.325000 | 00:17 |
| 136 | 0.150087 | 0.219485 | 0.274038 | 00:17 |
| 137 | 0.147386 | 0.202868 | 0.302244 | 00:17 |
| 138 | 0.147530 | 0.129326 | 0.273077 | 00:17 |
| 139 | 0.145539 | 0.096450 | 0.296474 | 00:17 |
| 140 | 0.145980 | 0.111623 | 0.300000 | 00:18 |
| 141 | 0.145903 | 0.138313 | 0.300000 | 00:17 |
| 142 | 0.150013 | 0.089761 | 0.275000 | 00:18 |
| 143 | 0.154749 | 0.164044 | 0.275000 | 00:17 |
| 144 | 0.149258 | 0.143600 | 0.280449 | 00:17 |
| 145 | 0.145224 | 0.149808 | 0.300000 | 00:18 |
| 146 | 0.140290 | 0.104018 | 0.277885 | 00:18 |
| 147 | 0.142366 | 0.178131 | 0.293910 | 00:17 |
| 148 | 0.149232 | 0.173077 | 0.275000 | 00:17 |
| 149 | 0.145681 | 0.137975 | 0.297115 | 00:17 |
Submission
embedding_model.eval()
test_metadata = metadata.loc[metadata['split']=='test'].copy()
test_metadata['cry'] = test_metadata.apply(lambda row: read_audio(row['file_name']).numpy(), axis=1)
grouped_data = test_metadata.groupby(['baby_id', 'period'])['cry']
cry_dict_test = {}
for key, group in grouped_data:
cry_dict_test[key] = {'cry': shuffle_group_and_concat(group, 7)}
with torch.no_grad():
for (baby_id, period), d in tqdm(cry_dict_test.items()):
cry_array = d['cry']
cry_encoded_list = []
for row in cry_array:
encoded_row = encode(embedding_model.cuda(), torch.tensor(row).cuda())
cry_encoded_list.append(encoded_row)
d['cry_encoded'] = cry_encoded_list
test_pairs['score'] = test_pairs.apply(lambda row: compute_cosine_similarity_score(row=row, cry_dict=cry_dict_test), axis=1)#submission must match the 'sample_submission.csv' format exactly
my_submission= test_pairs[['id', 'score']]
my_submission.to_csv('my_submission.csv', index=False)
display(my_submission.head())| id | score | |
|---|---|---|
| 0 | anonymous027B_anonymous212D | -0.120739 |
| 1 | anonymous035B_anonymous225D | -0.063723 |
| 2 | anonymous029B_anonymous288D | 0.026014 |
| 3 | anonymous001B_anonymous204D | -0.170518 |
| 4 | anonymous075B_anonymous244D | 0.125677 |